Why does my parallel code take much more time than a non-paralleled one?#
This question is often asked among scientists. Let’s say you have a function that takes a list of numbers and returns another list of the numbers, what could be the best way to parallelize this function?
from contextlib import contextmanager
from time import perf_counter
import math
@contextmanager
def timeit(description: str) -> None:
""" Simple timing context manager. """
start = perf_counter()
yield
t = perf_counter() - start
# pretty print time
units = [u"s", u"ms",u'us',"ns"]
scaling = [1, 1e3, 1e6, 1e9]
if t > 0.0 and t < 1000.0:
order = min(-int(math.floor(math.log10(t)) // 3), 3)
elif t >= 1000.0:
order = 0
else:
order = 3
t = t * scaling[order]
unit = units[order]
print(f"{description}: {t:.3g} {unit}")
from math import sqrt
with timeit("Sequential"):
[sqrt(i ** 2) for i in range(1_000_000)]
Sequential: 364 ms
from joblib import Parallel, delayed
with timeit("Joblib Parallel+delayed"):
Parallel(n_jobs=4)(delayed(sqrt)(i ** 2) for i in range(1_000_000))
Joblib Parallel+delayed: 4.86 s
from multiprocessing import Pool
with timeit("Multiprocessing.Pool"):
Pool().map(sqrt, range(1_000_000))
Multiprocessing.Pool: 220 ms
from multiprocessing.pool import ThreadPool
with timeit("Multiprocessing.ThreadPool"):
ThreadPool().map(sqrt, range(1_000_000))
Multiprocessing.ThreadPool: 184 ms
What is parallelism?#
In the context of scientific analysis, parallelism refers to the ability to perform multiple calculations at the same time. This can be achieved by using multiple processors or cores, or by dividing the calculations into smaller independent tasks and assigning them to different processors or cores. Parallelism can significantly speed up the time it takes to perform scientific analyses, such as simulations, data analysis, and machine learning.
Parallelism is not easy, and so not only does it take substantial developer time (the time it takes you to implement it), but there are computer-time costs to breaking down problems, distributing them, and recombining them, often limiting the returns you will see to parallelism.
Tip
Parallelism is the process of:
taking a single problem,
breaking it into lots of smaller problems,
assigning those smaller problems to a number of processing cores that are able to operate independently, and
recombining the results.
Limitations of parallelisation: Amdahl’s law#
There are a number of challenges associated with parallelism, such as ensuring that the different processors or cores are able to communicate with each other efficiently, and avoiding race conditions where the results of one calculation are affected by the results of another calculation. However, the benefits of parallelism can outweigh the challenges, and it is an increasingly important tool for scientific analysis.
Amdahl’s Law describes the theoretical limits of parallelization. If \(P\) is the proportion of your algorithm that can be parallelized, and \(N\) is the number of cores available, the fundamental limit to the speed-up you can get from parallelization is given by: $\(\begin{aligned}\textrm{total speed up} &= \frac{T_1}{T_N} \\ &= \frac{1}{\frac{P}{N} + (1 - P)} \\&\leq \frac{1}{1-P}\end{aligned}\)$
This analysis neglects other potential bottlenecks such as memory bandwidth and I/O bandwidth. If these resources do not scale with the number of processors, then merely adding processors provides even lower returns.
%matplotlib inline
import pylab as plt
import numpy as np
from mpl_toolkits.axisartist.axislines import AxesZero
P = np.array([0.2, 0.4, 0.6, 0.8, 0.95])
N = np.array([2 ** k for k in range(10)])
S_N = 1 / ((1 - P[:, None]) + P[:, None] / N[None, :])
plt.figure()
plt.subplot(axes_class=AxesZero)
for pk, snk in zip(P, S_N):
color = plt.plot(N, snk, 'o-')[0].get_color()
plt.text(N[-1] * 1.1, snk[-1], f'P={pk:0.1f}', va='center', color=color)
ax = plt.gca()
for direction in ["bottom", "left"]:
# adds arrows at the ends of each axis
ax.axis[direction].set_axisline_style("->")
for direction in ["top", "right"]:
# adds arrows at the ends of each axis
ax.axis[direction].set_visible(False)
plt.title("Amdahl's Law".upper(), fontsize='large', fontweight='bold')
plt.yscale('log')
plt.xscale('log')
plt.xlabel('N cores')
plt.ylabel('Speedup');
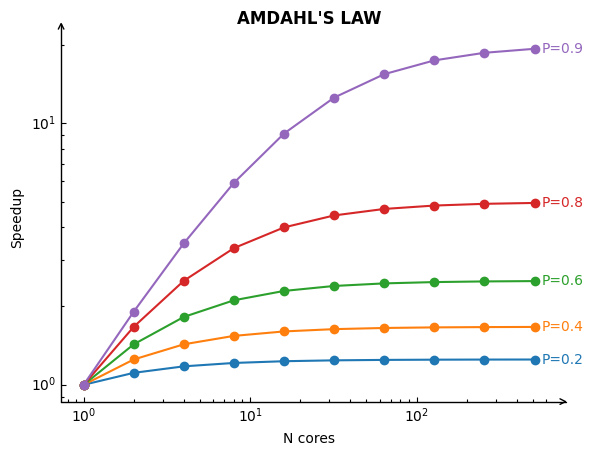
For example, if a task can be parallelized 80% (red curve above) of the time and there are 4 processors, the maximum speedup would be 16. This means that the task could be completed in 1/16th of the time it would take to run on a single processor. However, the Amdahl’s law shows that there is a limit to the speedup that can be achieved, no matter how many processors are used. This is because there will always be some part of the task that must be executed sequentially.
Amdahl’s law is a fundamental law of parallel computing. It is important to understand this law when designing or optimizing parallel algorithms.
The original Amdahl’s formulation was not explicit on so called “overheads” of going into parallel workflows. To understand the overheads, we need to list the primary steps of the parallel workflow:
Process-instantiations (”spawn”): Python first has to instanciate new Python processes (aka workers).
Data transfer: Python needs to move data around from the main process to the workers. Memory transfer could be expensive if objects are large.
Data collection: Python needs to retrieves the results from the workers in its main process.
Synchronizations: Sometimes individual tasks depend on the others’ progress and they have to await. This is expensive as the main process must collect states to inform the workers and workers are blocked until they ca continue.
Warning
Thread-based multiprocessing is in principle limiting these overheads (e.g. shared memory). However in Python, it costs even more because of the GIL, which forces serial execution of threads.
Back to our simple example#
The example code corresponds to the following pseudo tasks
[SERIAL]-<iterator> feeding [SERIAL]-function call storing into list[]
versus
[SERIAL]-<iterator> feeding [PARALLEL]-function call storing into list[] feeding into [SERIAL]-list collection
So, how to measure which solution is worth? How Much You Have To Pay?#
Benchmark, benchmark, benchmark.
Test and time the actual code on sufficient data to see what is going on.
Note
benchmark can also depend on your platform and the present workload of it. If your machine runs other heavy computations, or if it runs out of memory, the benchmark will be affected.
from math import sqrt
N = 1_000_000
with timeit("Serial"):
[sqrt(i ** 2) for i in range(N)]
with timeit("Joblib Parallel+delayed"):
Parallel(n_jobs=-1)(delayed(sqrt)(i ** 2) for i in range(N))
with timeit("Multiprocessing.Pool"):
Pool().map(sqrt, range(N))
with timeit("Multiprocessing.ThreadPool"):
ThreadPool().map(sqrt, range(N))
Serial: 383 ms
Joblib Parallel+delayed: 4.56 s
Multiprocessing.Pool: 160 ms
Multiprocessing.ThreadPool: 98.5 ms
Important
The overheads of parallelization are significant and depend on which library you are using. There are good reasons to prefer some libraries over others (which we do not discuss here).